Tsonnet #14 - Where’s Wally? Adding parsing error tracing
Transforming cryptic error messages into helpful visual cues

Welcome to the Tsonnet series!
If you're just joining, you can check out how it all started in the first post of the series.
In the previous post, we added lexing error tracing.
This time, we will expand it and cover parsing error tracing.

A parsing error
Let’s add an extremely simple sample file introducing a parsing error:

Even though this example is pretty simple, it serves us well to pinpoint the parsing error. We have a number and a boolean, which are lexed correctly, but the expression is invalid; we can’t add a number to a boolean.
Jsonnet highlights row and columns correctly, but there’s no visual cue to help us:

But we want to do better at this front and also add human-friendly error messages to Tsonnet.
Let’s also stretch a little bit and add a multiline sample file:
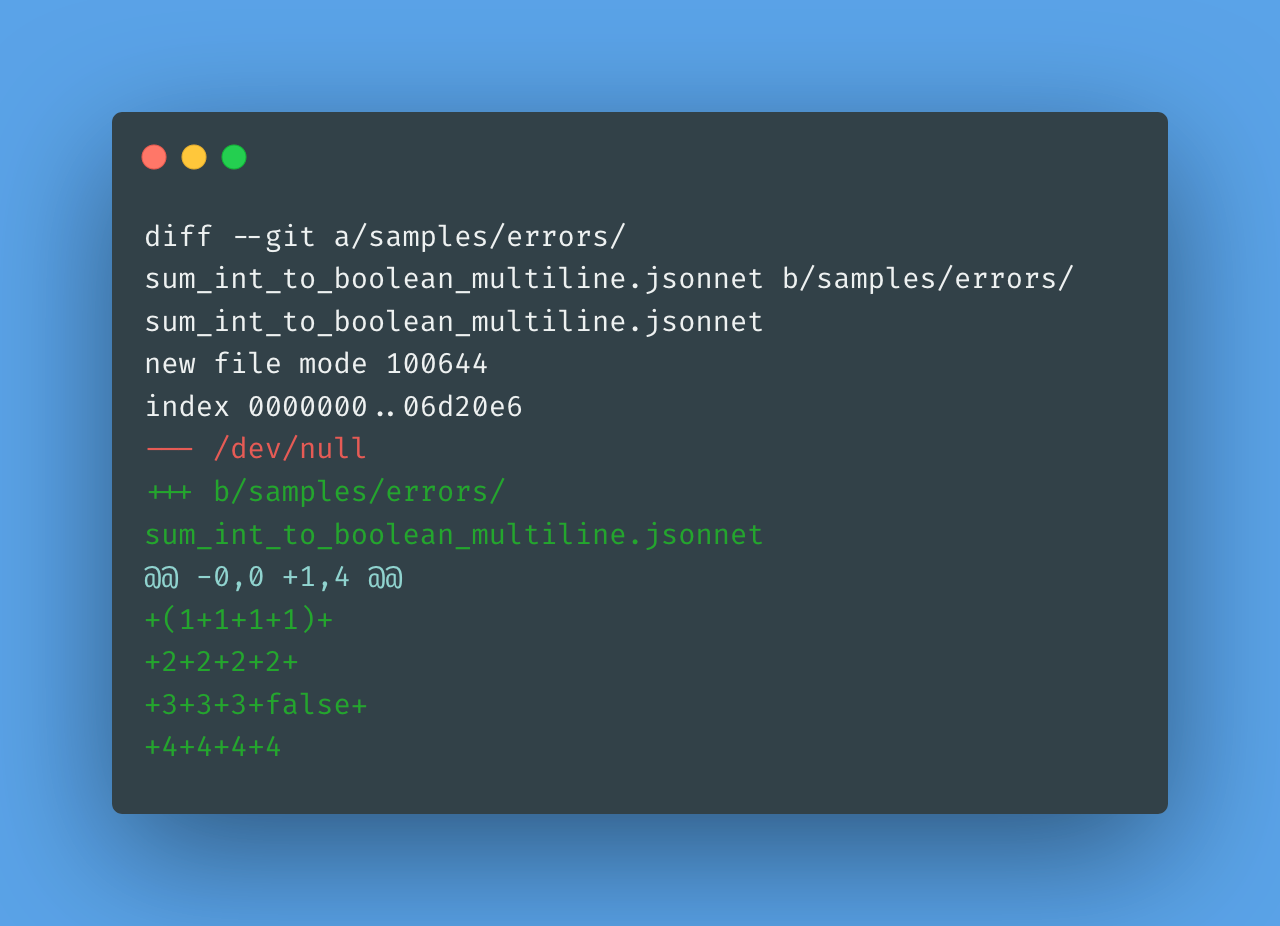
Considering that a parsing error can arise at any part of the entirely valid lexed file, we need to make sure that parser errors are captured at the right position.
Now that we have samples to test against, we need a way to capture where each token was found. Let’s see how to capture parsing positions.
Capturing parsing positions
The first file we need to update is the ast.ml. We need to capture the position in the AST:

It is important to have both the start and end positions of the expression. The new position type should be part of the expr.
So far, expr was a sum type containing all the value variants that could be found in the code. Now, it will be the product type that contains position and value.
The pos_from_lexbuf function will come in handy to capture the position for lexing errors.
Now we need to do some refactoring-driven-development to update everywhere referencing the expr to use value where it’s due.
The json.ml change is straightforward — only replace expr references to value:

Now, let’s see how to capture the positions in the parser.
Parsing positions
Menhir provides some helpers, and the $startpos and $endpos are the ones we are interested in, which return a Lexing.position.
We can wrap the record building in the with_pos function to make the parser cleaner. But we’ll need to update every single rule in expr to use it:
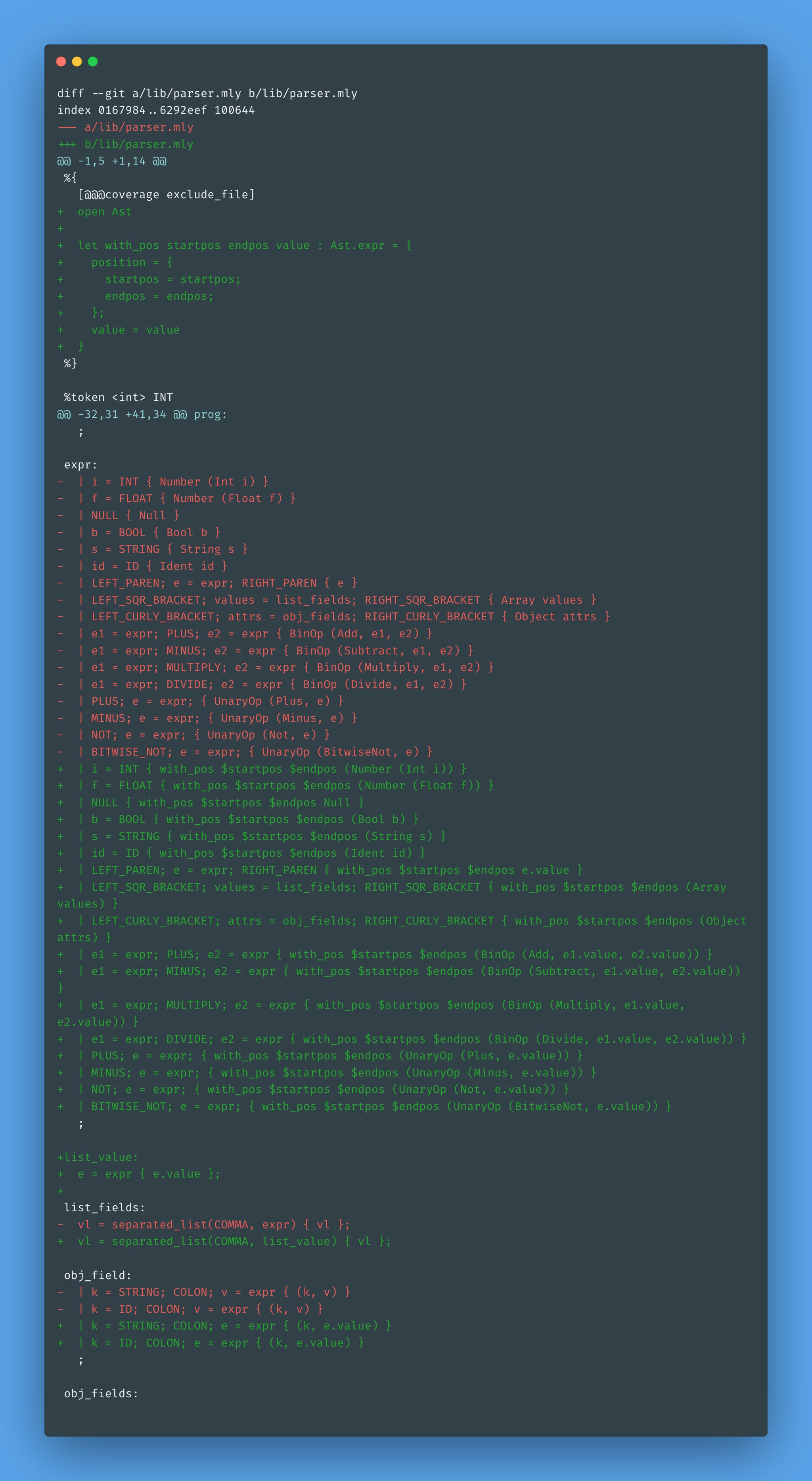
Helper rules such as list_value, list_fields, obj_field, and obj_fields do not need to include the position. At least, not yet. Maybe soon, when the type checker is implemented, we’ll need it to highlight errors for the expression’s inner tokens. Let’s postpone this to the time it is needed, if it is needed at all.
The parser had many lines changed, but it couldn’t be simpler than that.
The error-handling is being exercised by the interpreter until now, but it will be better to isolate it in its own module. Let’s do it before continuing.
Introducing the error module
With an error.ml module, we can encapsulate all things related to error formatting. It makes things easier to reason about in a contained context:

The error.mli interface file has been added to expose only the trace function from the Error module:

Some new things have been introduced here, compared to the previous format_error function:
It handles multiline files.
We are skipping lines without error. Showing non-relevant lines only adds noise.
It has a clever logic to highlight the errors from the expr’s start column till the end column.
Cool, huh?!
Let’s proceed to connect the pieces.
Connecting all the pieces
The interpreter needs a few tweaks:
The
parsefunction needs to be refactored to use the newError.tracefunction.Functions such as
interpret_arith_op,interpret_unary_op, andinterpretneed to be changed to deal with thevaluefromexpr.
The diff might be daunting to stare at, but its complexity hasn’t increased much:

Let’s update the tests:
Add a new cram test against
samples/errors/sum_int_to_boolean.jsonnet.Add a new cram test against
samples/errors/sum_int_to_boolean_multiline.jsonnet.Run
dune runtest.Run
dune promote.
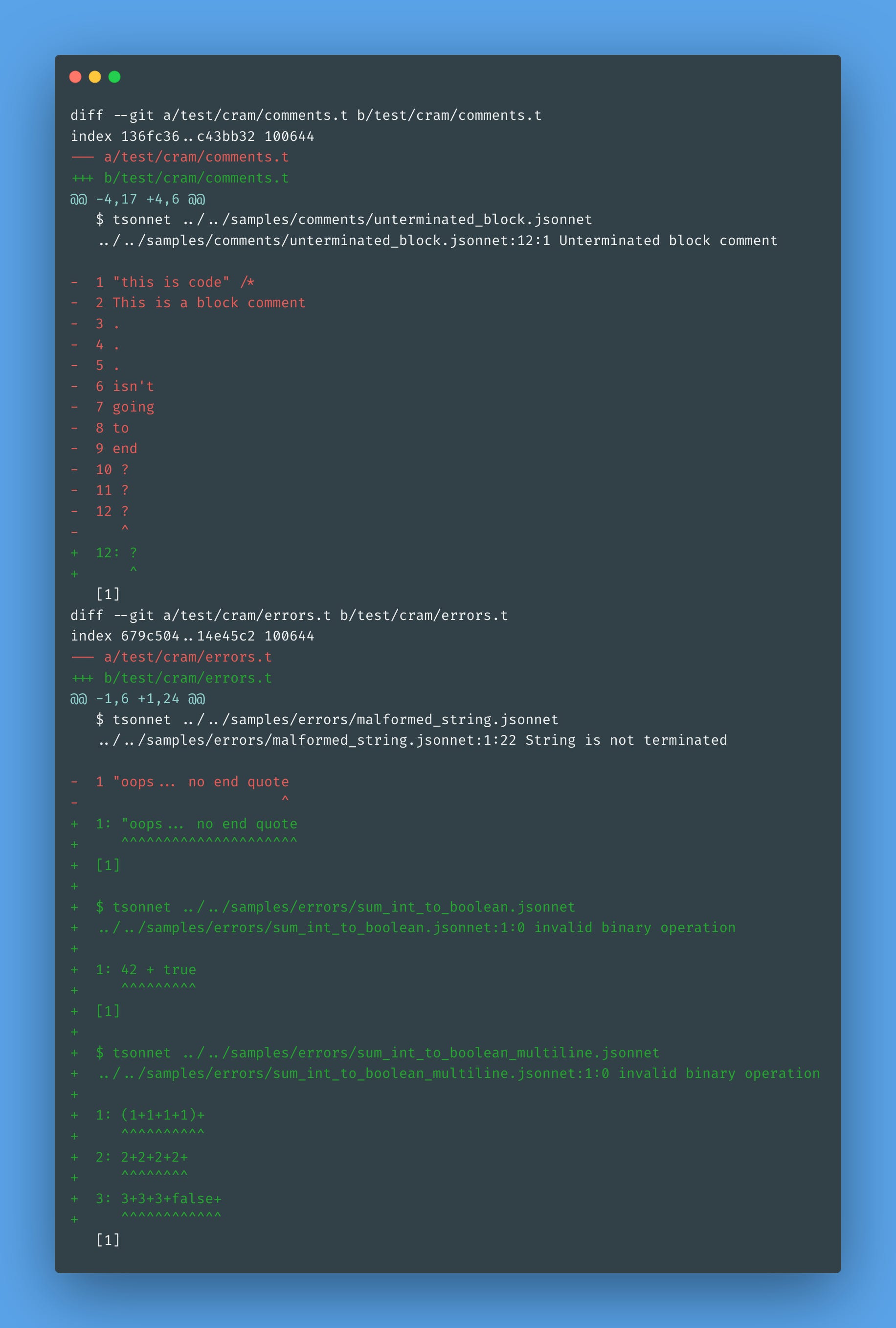
Look at this beauty! Errors are now much easier to spot.
Conclusion
We've successfully extended our error-handling capabilities to pinpoint parsing errors with clear visual highlighting. This makes debugging and development in Tsonnet significantly more user-friendly, as developers can quickly identify and fix issues in their code.
We've built a robust foundation that can be expanded for future features like type checking. The changes required extensive refactoring, but the results were worth it.
See you in the next issue!