Tsonnet #13 - Carets, columns, and clues: adding lexing error tracing
Because good debugging starts with knowing where to look

Welcome to the Tsonnet series!
If you're just joining, you can check out how it all started in the first post of the series.
In the previous post, we added unary operations to Tsonnet:

And today, after a few days of pause, we're back to Tsonnet. It's Friday and this is the post #13 — it would be funny if it were Friday the 13th, talking about the monsters of programming language usability: dealing with errors.
Until now, Tsonnet has only had rudimentary error reporting and no error tracing. To grow its complexity, we need to start tackling errors deliberately and methodically.
Let's start with the errors encountered during the lexing phase.

Jsonnet lexing errors
Here's the output of Jsonnet for the 2 errors covered by the cram tests so far:

It contains the filename, followed by a colon, the line number, another colon, the column number, and the error message. It also shows partially the file content. The malformed string example has just one line, so it output its entirety. In the second example, it shows only the first line, indicating that on column 16 is where the multi-line comment started, but did not terminate.
Could be better, but the relevant bits are there.
Tsonnet is not friendly at all yet:

But that's why we are here today. It is about to change!
Adding lexing error tracing
The entrypoint of Tsonnet has been reading the entire file and passing the content around. This left the lexer blind to the context, dropping the filename from the context.
We need to change it. Let's pass the filename to Tsonnet library instead, so we can use this information later:

The filename can now be passed to the parse function. Now the lexer will operate on the IO channel, rather than a plain string, closing the channel when we are done with IO. We also need to set the filename to the lexer, indicating the current open file. The new format_error function will wrap the error message around a formatted message, containing the filename, line, and column where the error was raised:

As indicated by the Lexing module documentation, the difference between pos_cnum and pos_bol is the character offset within the line (i.e. the column number, assuming each character is one column wide). Otherwise, pos_cnum gives us the char position relative to the beginning of the file, not the line.
I found a small bug where the multi-line comments were not accounting for line breaks. Easily fixable by calling new_line before proceeding:

After that, we can run dune promote to update the cram tests accordingly:

And with that we have line and column where the lexing error happened.
A nice improvement. Can we do better?
We can do better
We have the filename, the row, and colum numbers. If we think for a moment, having this information allows us to pinpoint where is the error in the source code.
A simple way of doing it is to print the file content, and use the row and column information to pinpoint it.
As we are dealing with lexing errors, the lexer will stop as soon as it finds the error. We can take advantage of that and plot a caret symbol right after the faulty row. The function plot_caret draws empty spaces and the caret symbol highlighting where the problem is — we append this line to the end of the file content. The function enumerate_file_content reads the file and enumerates each line, and since it is performing IO, the format_error function needs to return a result instead of a simple string and we bind the result to error:
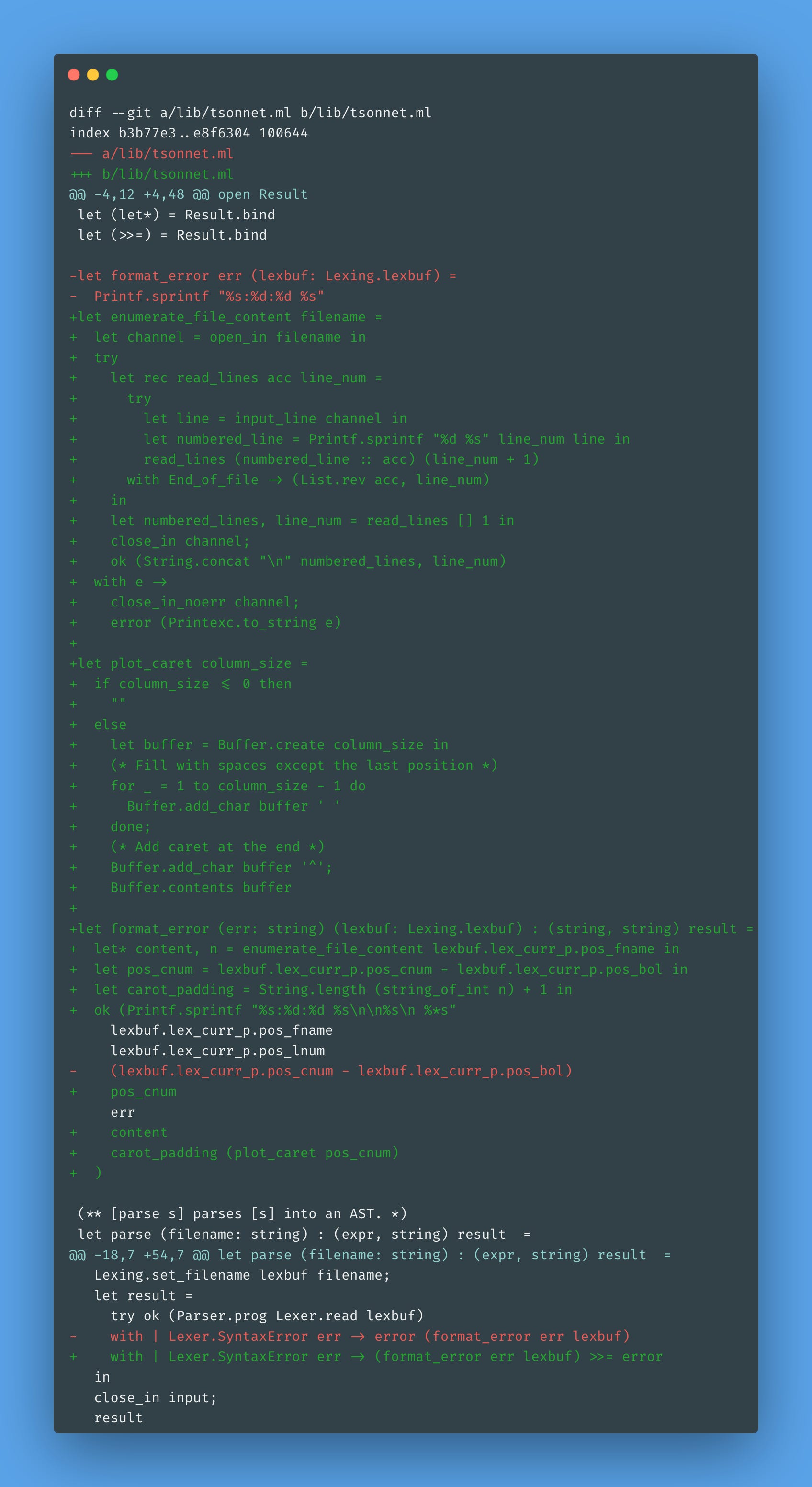
The implementation is a bit naive and not performant for now. This is a trade-off I'm happy to make, considering the language is far from done.
Now, let's run dune promote to update the cram tests:
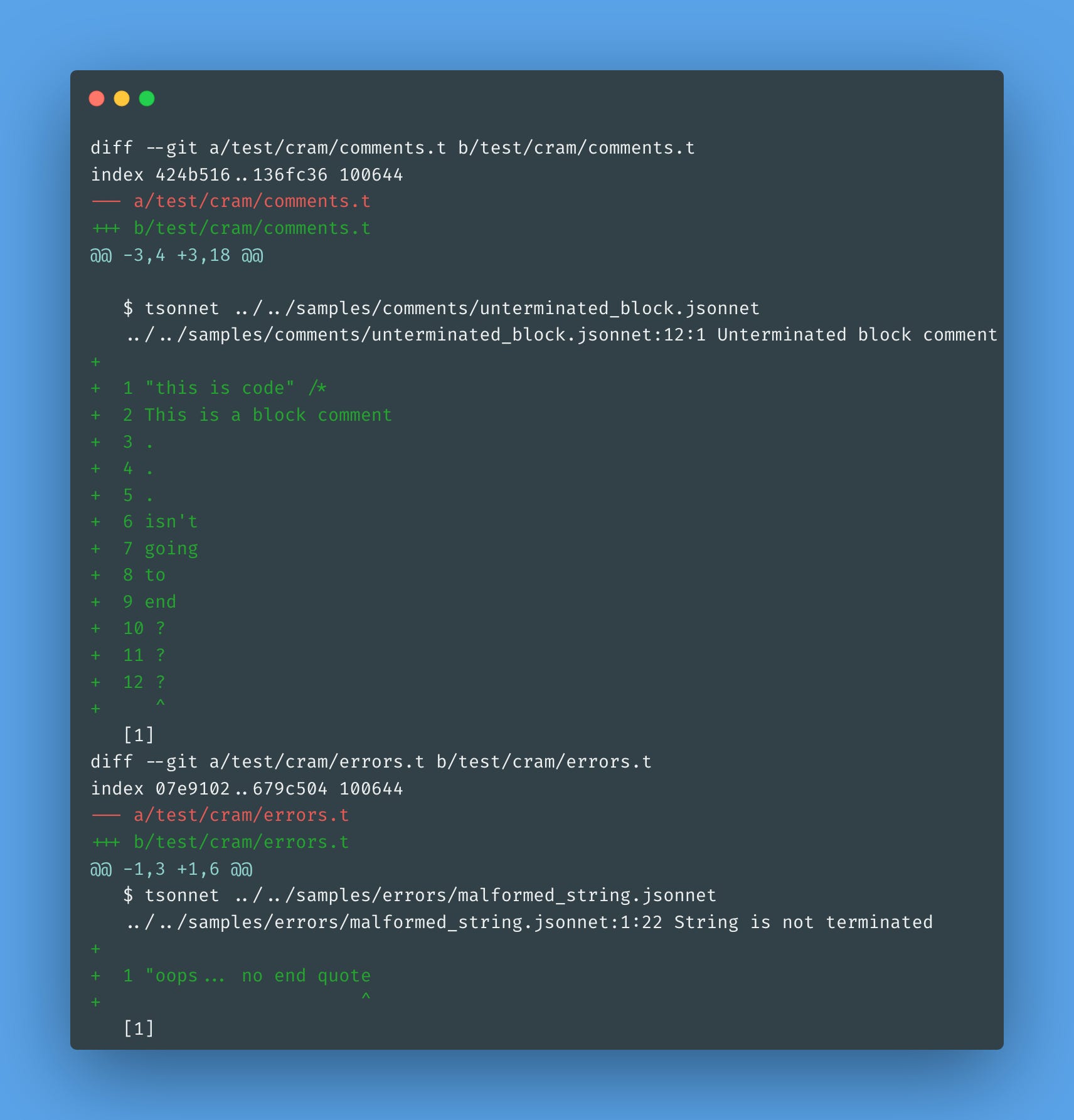
And, ta-da! Error messages for humans.
Concluding
As I mentioned before, the implementation here is simple and naive, but I’m ok with that for the time being. We don't have even imports implemented yet. Also, this is just the tip of the iceberg. It covers only lexing errors. We still have to deal with parsing errors, and eventually, type checking errors.
I've drawn inspiration from Elm and the blog post Compiler Errors for Humans — it is nearly a decade old and still inspiring to read.
I want Tsonnet to have error tracing that is as human-friendly as possible. Who's with me?