

Tsonnet #9 - ID please
Adding support for identifiers

Welcome to the Tsonnet series!
If you're just joining, you can check out how it all started in the first post of the series.
In the previous post, we fixed error handling during lexical analysis:

Now, let's continue building our interpreter by adding support for identifiers.
What is an identifier?
An identifier is a sequence of characters that serves as a name for various programming constructs, such as variables, functions, classes, or modules.
When we added object literals to Tsonnet, we used strings as object attributes. However, it's more common to use identifiers for attribute names. Let's modify our object literal sample to use identifiers for some attributes:
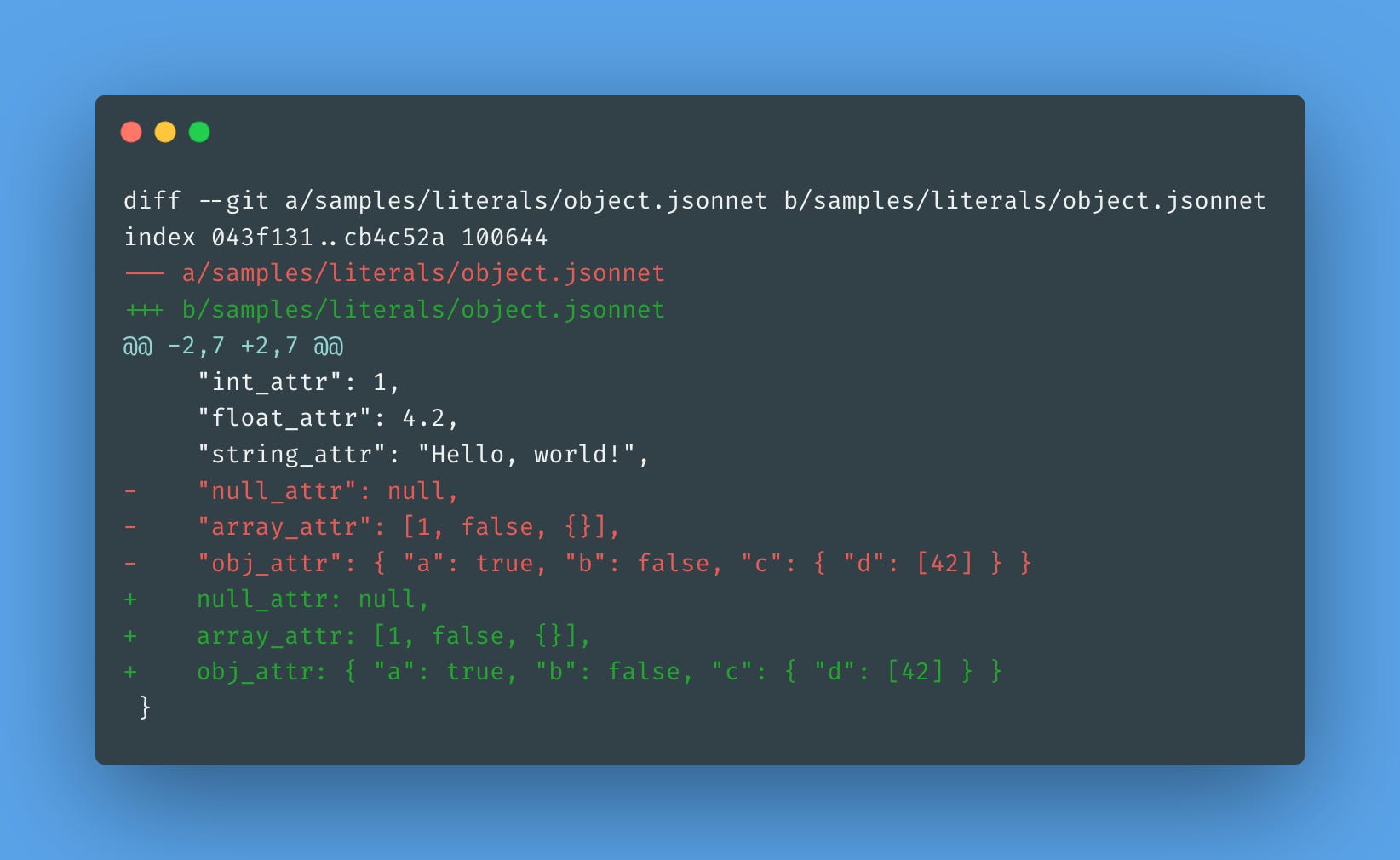
Running this code currently breaks our parser:

Let's fix this by implementing identifier support.
Adding identifiers
First, we need to add a new expression type to our AST:

Next, we need to define the lexical rules for identifiers. An identifier can start with an underscore or a letter, followed by any number of alphanumeric characters or underscores:
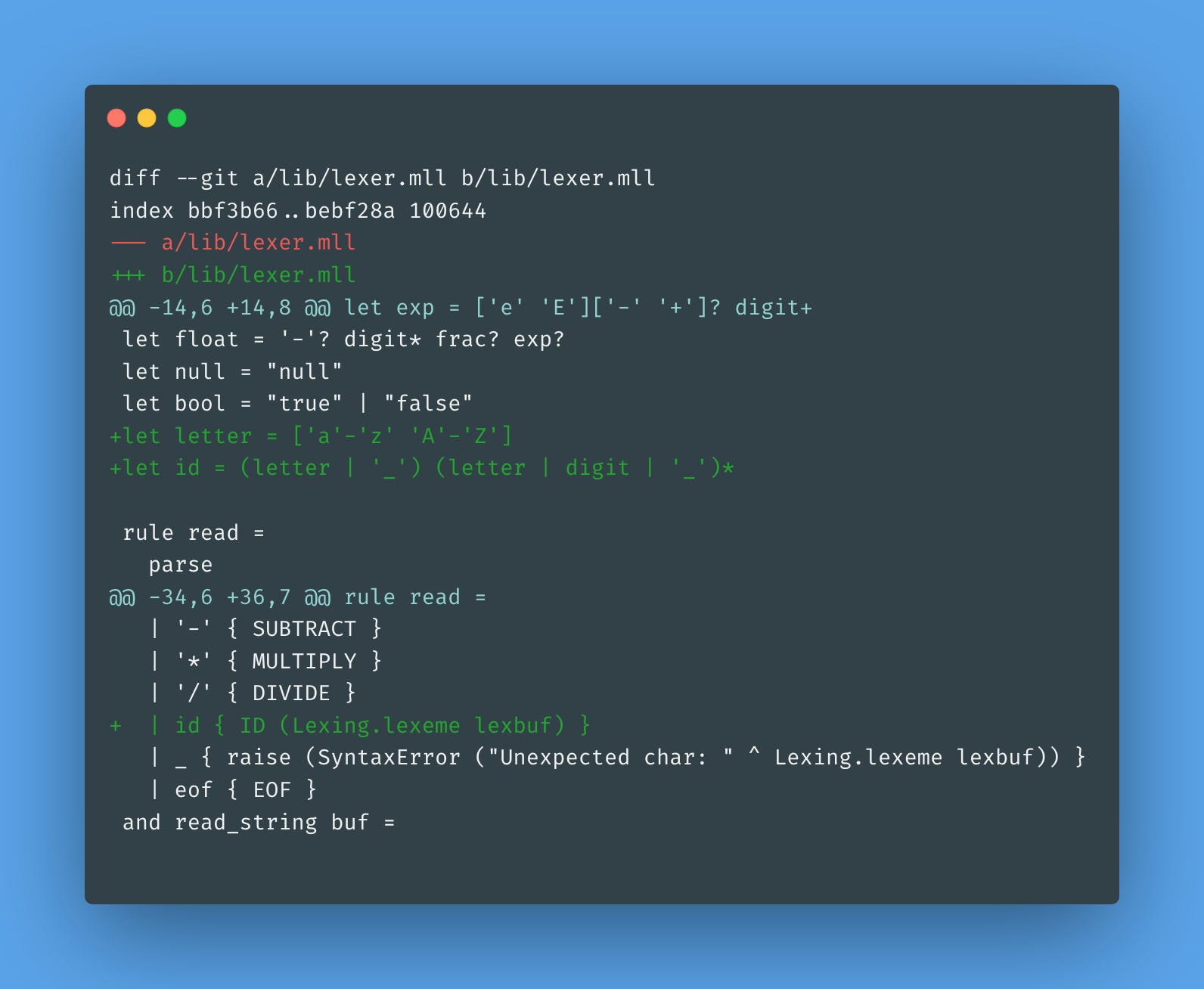
The lexer reads characters from the input and wraps them in the ID token type. The parser needs a few more changes to handle these new tokens:

We add the ID token type that will be parsed as a string. The new rule to match ID is straightforward. Finally, we update obj_field to handle both string and identifier keys.
The last step is to update our Tsonnet.interpret and Json.expr_to_yojson functions to handle the new Ast.expr type:

Conclusion
With these changes, we've successfully added identifier support to Tsonnet! This is a crucial feature that paves the way for more advanced language constructs. In upcoming posts, we'll build upon this foundation to add even more interesting features.
Stay tuned for the next post in the series!