
In the previous post, I bootstrapped the Tsonnet project and implemented the parsing of integer literals.
Tsonnet #0 - From Zero to Interpreter

This is the first post where I'm going to dive in the process of developing Tsonnet. Welcome to the series!
In this post, let's continue parsing other literal values.
Let's start with the most boring and dreaded value: null.
Parsing nulls
We need to add null to our expr type:

The lexer:

And the parser:

The OCaml compiler now complains that the pattern matching on the print function is missing the Null type. We need to fix that:

With null implementation complete, let's move on to handling floating-point numbers.
Parsing floats
Again, adding float to the expr type:
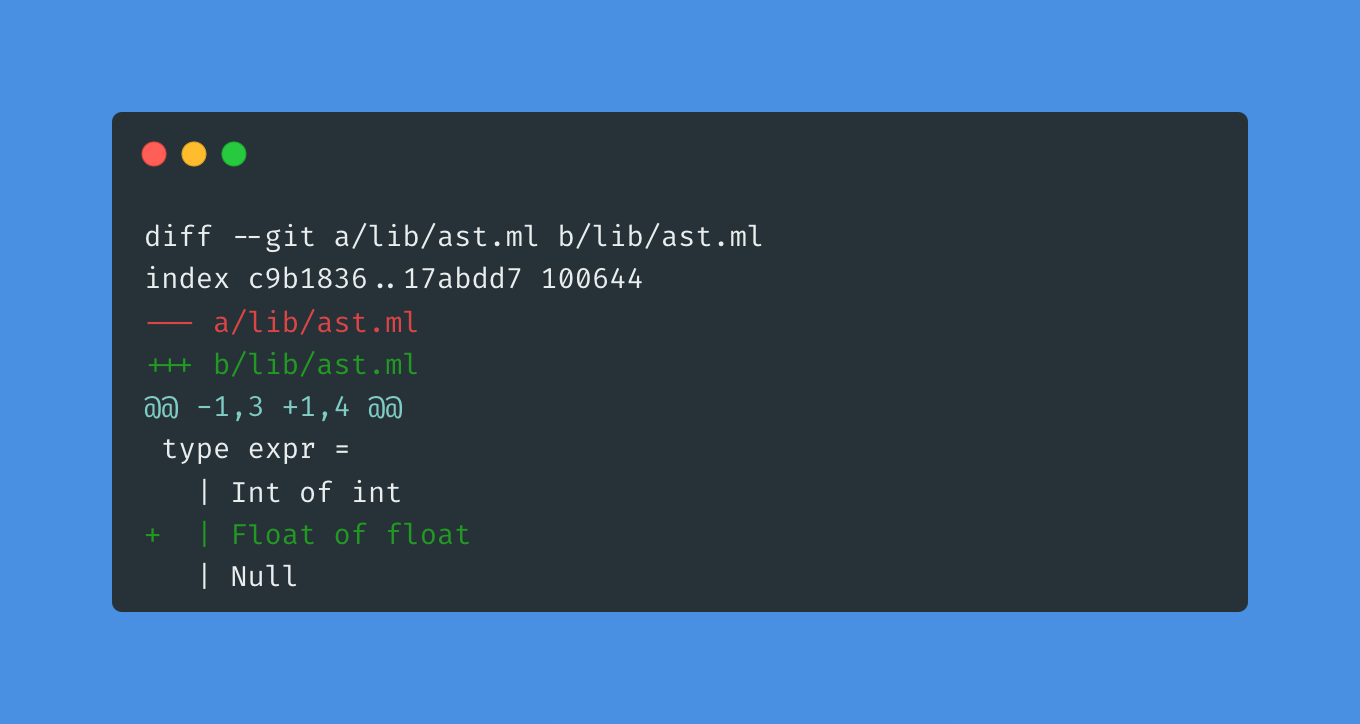
The lexer needs a little bit more of attention now:

We add few patterns (frac, exp) to make it easier to add the float token definition. This will allow us to write floats in multiple formats such as `4.2, `.42`, `4.e2`, `+4.e-10`, etc.
In the rule function, the lexer function call Lexing.lexeme lexbuf is going to return the value for us as a string. We need to convert it to float using the float_of_string.
The parser doesn't need to do much after that:
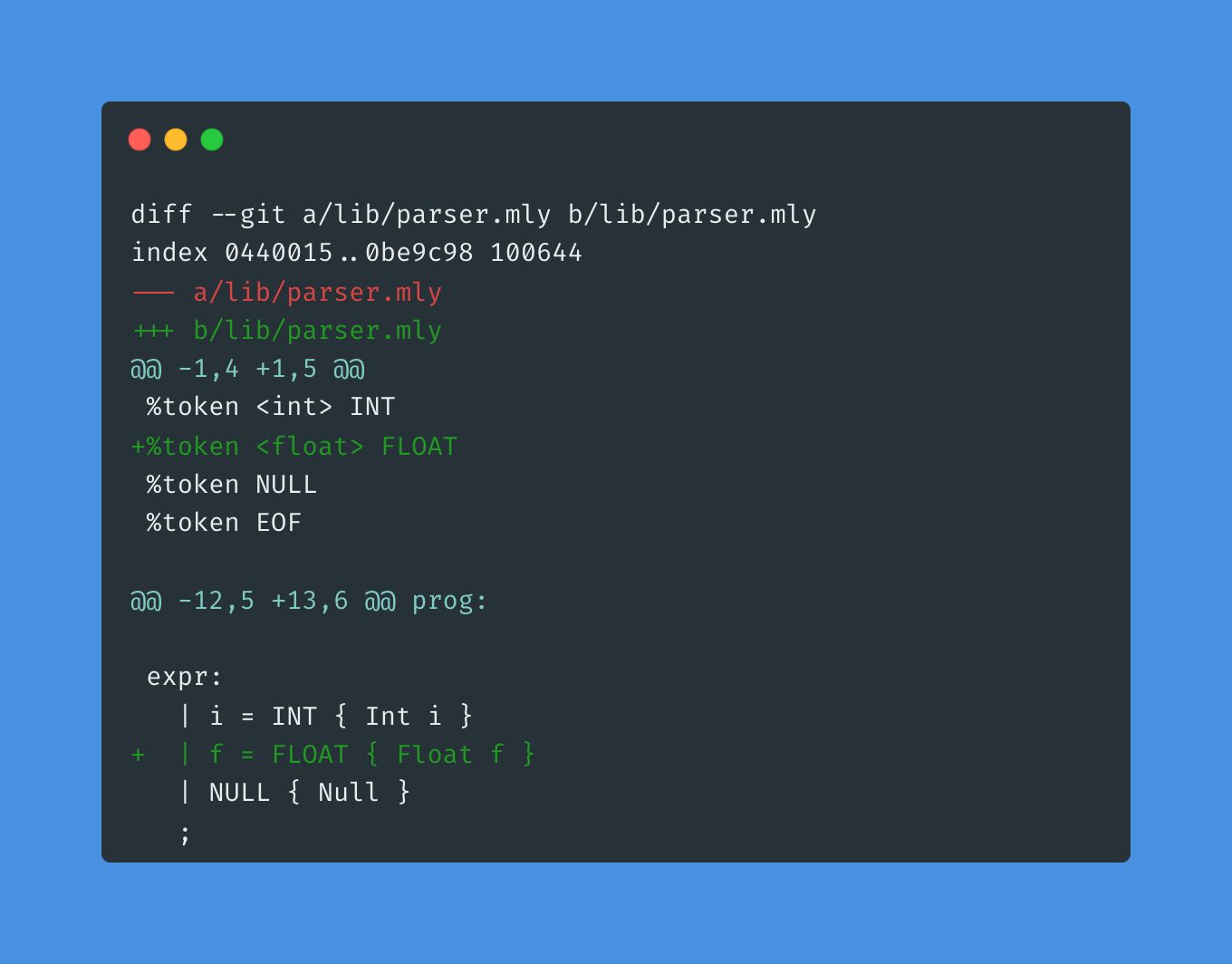
And the print function:

Now that we've handled numeric types, let's implement boolean values.
Parsing booleans
It's becoming repetitive and booleans are boring, you got the idea from the previous examples, so here's the entire diff:

With primitive types (numbers and booleans) in place, it's time to tackle string parsing.
Parsing strings
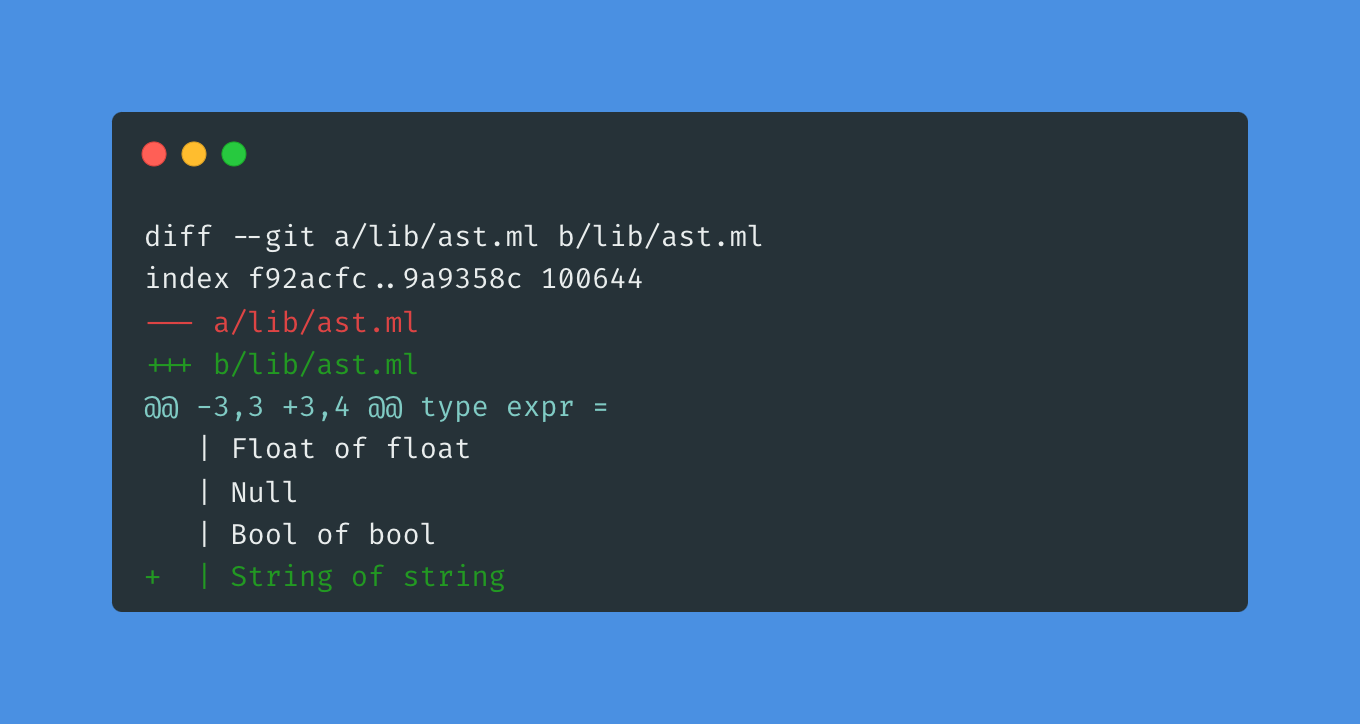
Strings need to be handled with extra care when tokenizing them:

Here we define a new exception SyntaxError to handle typos and unexpected syntax--we were missing it before. The error handling deserves careful attention. Nobody likes to use a programming language with cryptic error messages. But we are not there yet, so I'm postponing the friendlier error messages to a future iteration.
The rule read as soon as it matches a double-quote opening will call the supplementary rule read_string and pass a Buffer of size 16--the buffer size increases automatically if the string needs to allocate more than that.
The read_string rule will call itself recursively, handling escapes sequences, until it finds a closing double-quote, signalling the end of the string. In case of a illegal char or the lexer reaches the end of the file before the closing quote, an exception is raised.
Following to the parser and print function, the implementation is straightforward:

Disclaimer: it's worth noting that ocamllex is not unicode friendly. I want Tsonnet to support unicode, but I'm postponing this complexity for later. Perhaps using the sedlex package for that.
Having implemented all the basic JSON types, we can now move on to composite types, starting with arrays. Arrays present our first challenge in handling collections of values, and they'll require us to make our expression type recursive to support nested structures.
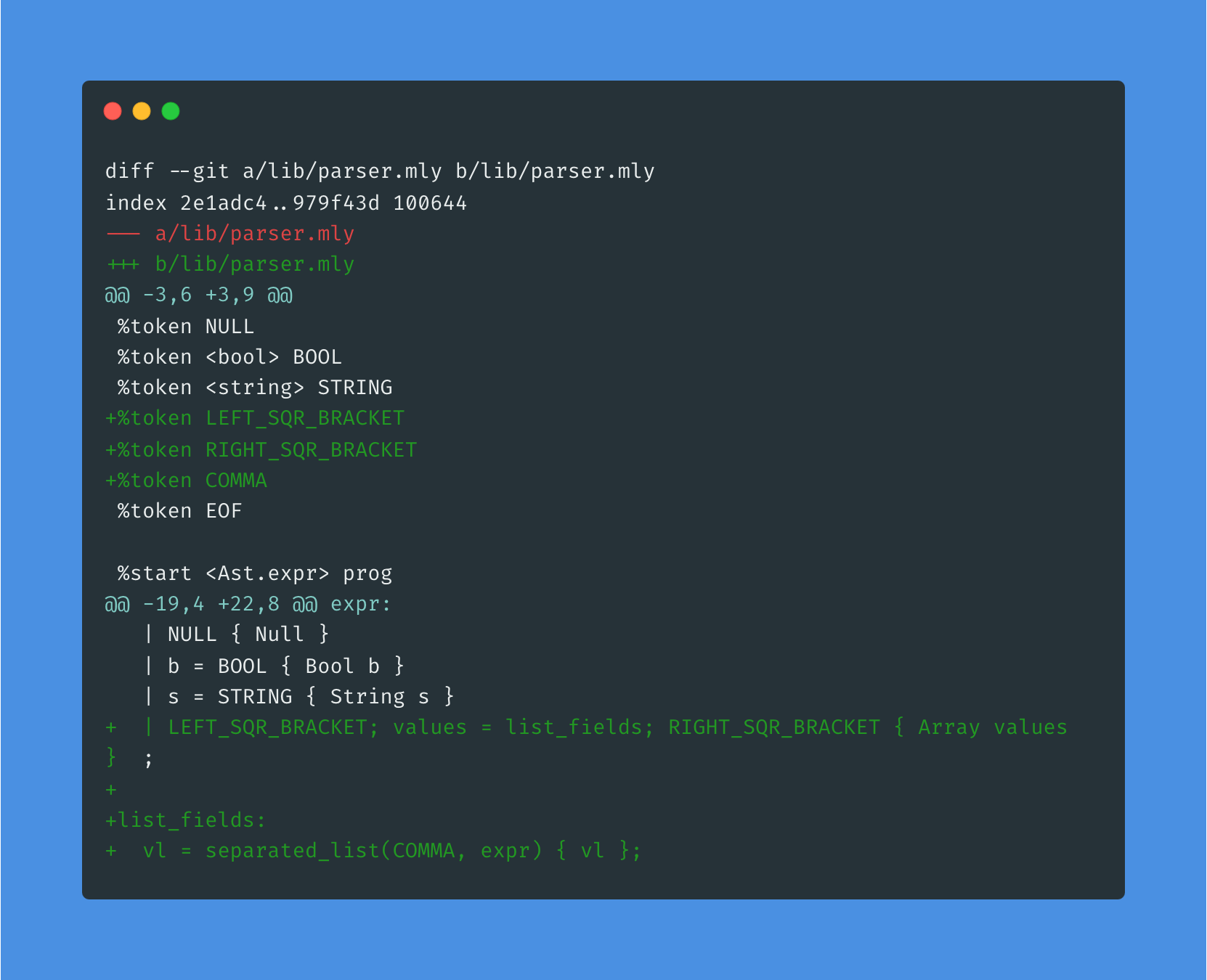
Parsing arrays
Arrays deserve a bit more of attention. During parsing, each value will be an expression. Fortunately, OCaml's type system is expressive enough to allow recursive type definitions, so we can self reference the expr type and since we want Tsonnet arrays to be immutable, let's use a list of expr:

The lexer already has code to tokenize the expressions, but we are missing the square brackets and comma tokens:
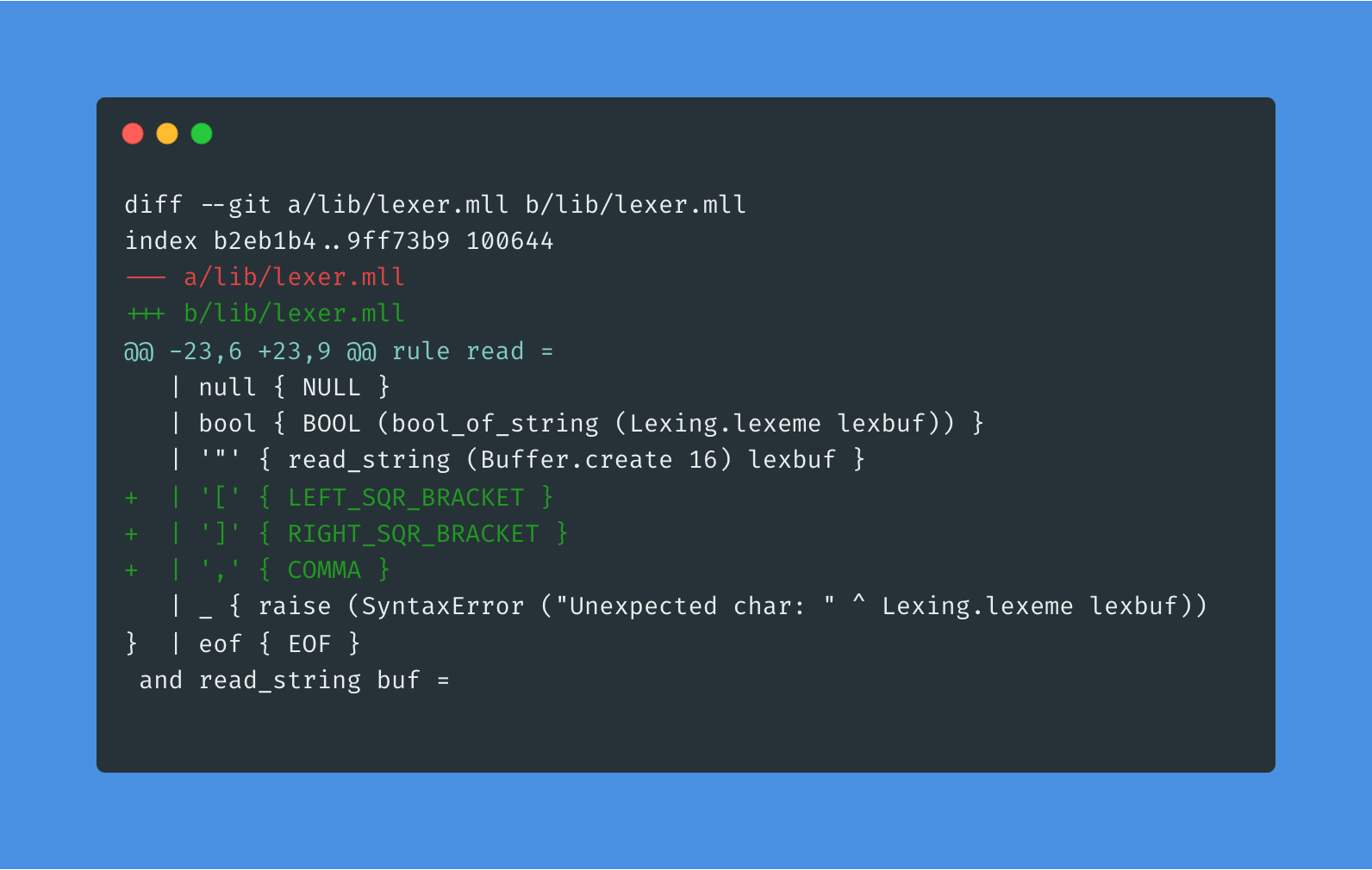
Menhir has the helper function separated_list to facilitate parsing values separated by a token. It fits like a glove for arrays!
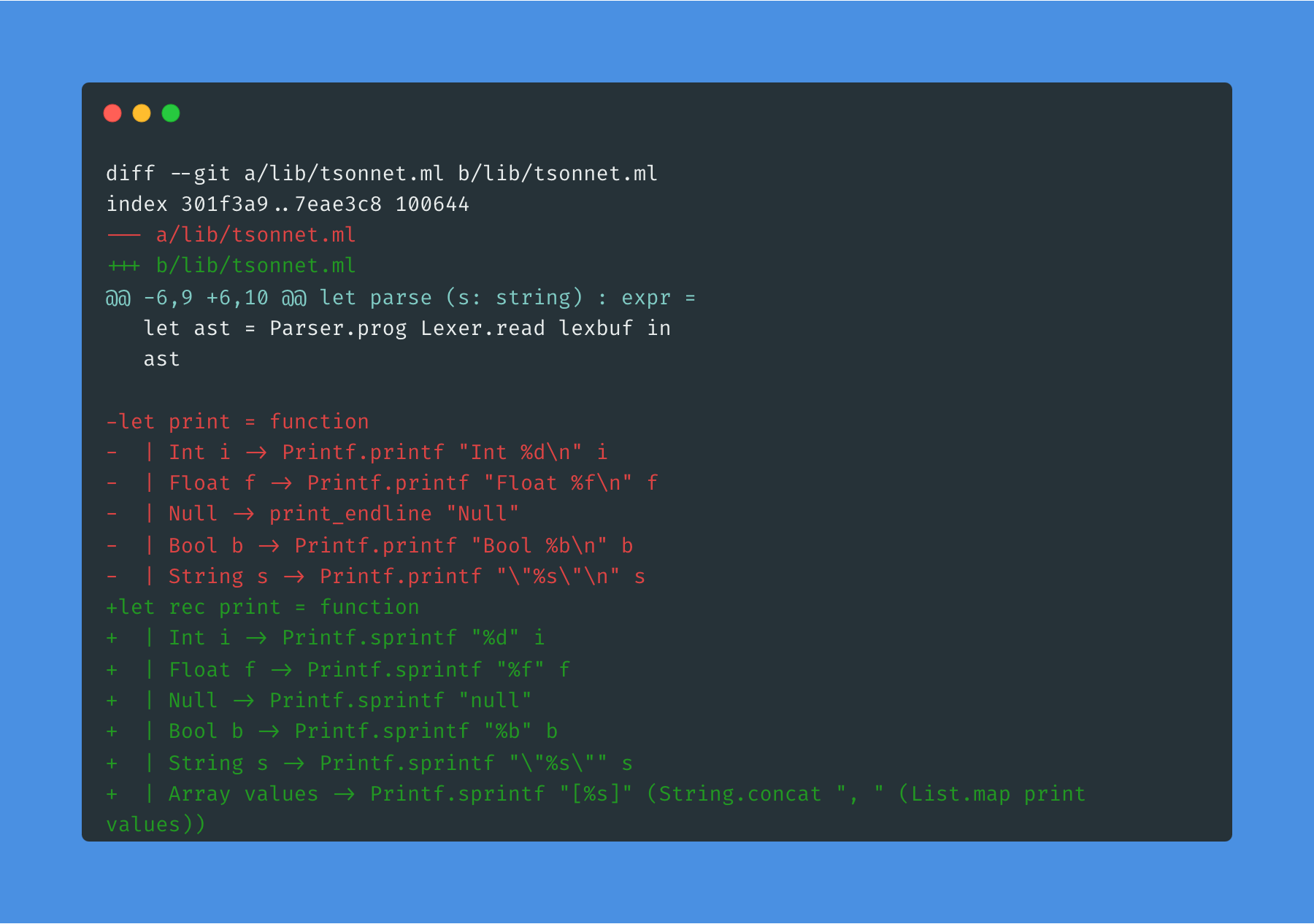
The print function now needs to be converted to a recursive function to handle arrays:
Building on our array implementation, we can now handle objects — the most complex JSON type. Objects are similar to arrays in that they're collections, but they introduce the additional complexity of key-value pairs and require careful consideration of lookup performance.
Parsing objects
An object is a collection of string keys containing expressions as values. I'm keeping it as a list containing tuples (key, expr) for now, for the sake of simplicity:

Later on, it might be worth using a Hashtbl to improve performance lookups for attributes and methods. Right now, we don't have this need yet. I'm going to refactor the object definition when the time comes.
The lexer and parser need only to be updated to add tokens for the curly brackets and colon symbols and the print function is almost the same as for arrays:

Formatting the JSON output with Printf is becoming annoying and doesn't scale properly, but we'll come back to it soon.
Concluding

So far, so good! We can now handle plain JSON.
I've been ignoring an important part, super relevant to guarantee the language spec in meeting its requirements: tests. We can't proceed without tests. I'm excited to share how I'm using cram tests to write automated tests.
Until then!