
Standard ML idiosyncrasies

I've been reading the book Modern Compiler Implementation in ML lately. It's been helpful to brush up on some concepts while developing Tsonnet (my typed-aspiring Jsonnet flavor) and I hope to learn a ton more. However, I'm growing dissatisfied with some details — not specifically the book, but the choice of the development environment.

I've been postponing writing this rant due to some life events, but I'm finally leaving here my impressions, maybe it's helpful to someone, or not... maybe it will only echo in the void. Anyway!
The (S)ML experience
The first thing I'm not happy with is the lack of a useful getting started guide. You know, the basics: how to compile programs, check standard library documentation, etc. The usual stuff you desperately need when you're starting in a new language. They are available on the website, though you need a few hops to find it, and I don't wanna read a 300ish page tutorial to learn how to do a simple "hello, world". Oh, come on!
Loading the REPL with your code is straightforward with sml myprogram.sml. This is fine, but I miss a way of simply running the file directly and getting its result — or better yet, compiling it to a binary (more on this frustration later). The REPL will evaluate the program as you load, but changing and doing it again is rather inconvenient.
The SML Environment editor extension was quite useful in improving the feedback loop while coding.
If you wanna load the REPL with a more complex code you wrote, like multiple modules, you can do so with sml -m sources.cm — where sources.cm is the manifest containing the list of all your program sources (the cm extension stands for CMake):
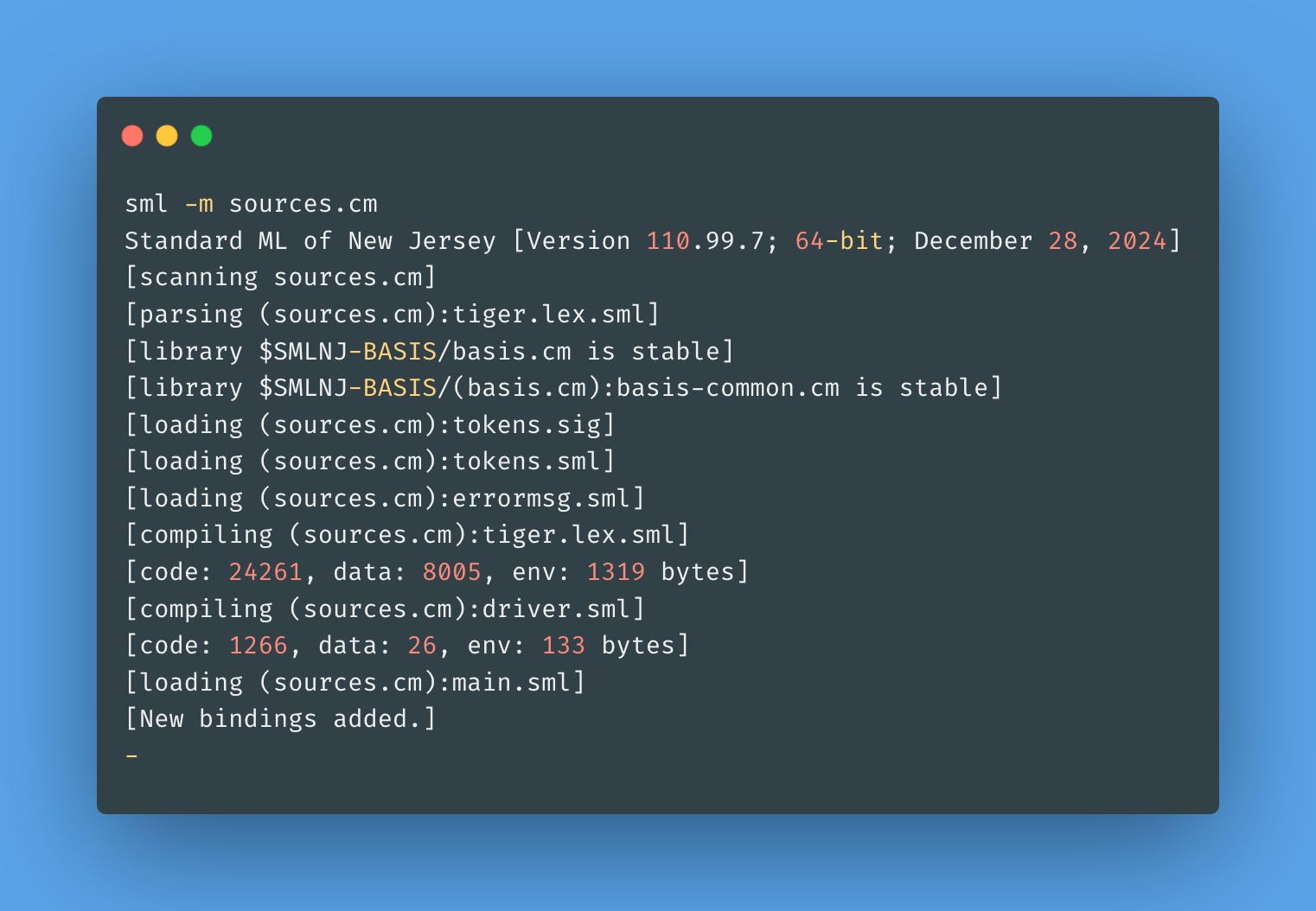
If you type something wrong, you need to drop characters using backspace — if you use arrows, well, no arrows for navigation within the REPL:

The REPL is not that helpful. I think I'm spoiled by utop, ghci, irb, and others.
Now, if you want to compile your program, you can use ml-build:

So far, so good. But here's what happens when you try executing it:

Uh oh!
Turns out, SML/NJ is compiled to an IR (intermediary representation).
To execute it, we need to feed the IR to sml like this:

Nothing absurdly wrong with it. It's just not straightforward.
As an alternative, MLton can compile directly to binary. It's great in theory! But here's the catch: if there's a library targeting SML/NJ, there might be some inconsistencies and code won't always work out of the box. After some attempts, I reluctantly gave up on MLton to be able to reuse the code from the book without constant tweaking.
I'm not happy having to deal with a not ideal environment for learning, but what could I expect, the book is dated now (1995), still, I had higher expectations regarding its basic usage. I wonder if I have chosen the C or Java version would be better — this is on me, I'm an eternal believer in the functional style and assumed it would be nicer to use (S)ML rather than C or Java.
Then, I thought: why not switch to OCaml? It's a better flavor of ML, and a very useful one, with plenty of tools and libraries. I can figure out the tools by myself. However, as I intend to keep reading the book and doing the more advanced exercises, I think I will stick to SML for the time being, otherwise, I won't be able to use some of the tools available — I hope I don't regret this decision.
Speaking of which, I had to implement a lexer as an exercise, using ML-Lex. I felt dumb through the trial and error process, experimenting with the sample code on the documentation page, which leaves much to be desired to say the least. Good thing that nowadays we have LLMs, and Claude came to the rescue — it was a relief having an AI pairing pal to guide me on some basic stuff, instead of extending the frustrating moments.
In the book, we build a lexer a language called Tiger. Here's the lexer I wrote:
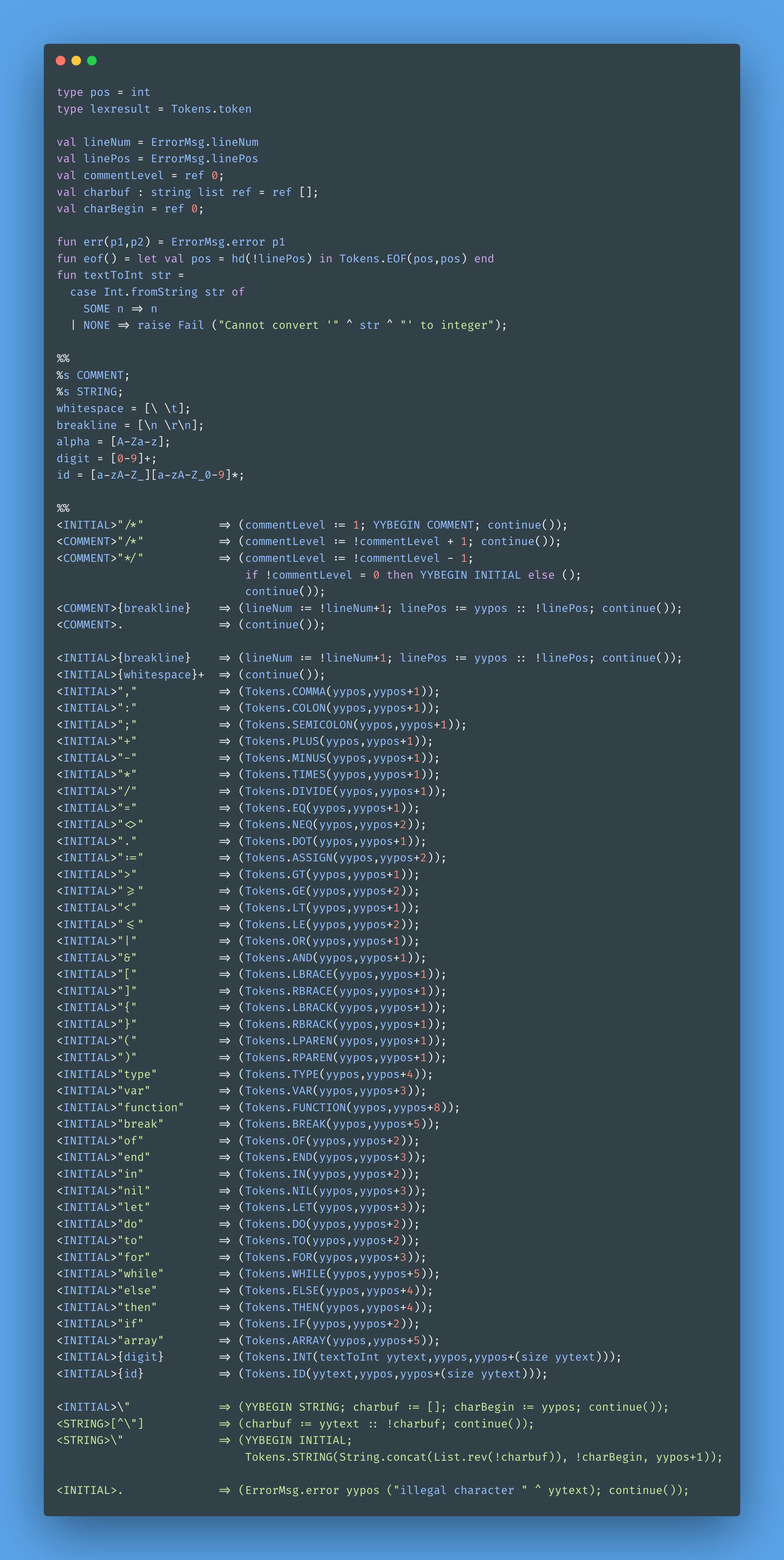
The ML-Lex documentation is rather cryptic when it comes to dealing with states, how to use it, and so on. Lucky me I was able to hook a piece of information from chapter 2, talking about how automata are suitable for implementing lexers to figure it out, and then came up with COMMENT and STRING. I wonder how many people gave up by just trying the "official" documentation and getting frustrated. I'd probably give up without the extra external context.
Conclusion
I've rambled enough for one post. I may write more about my ML adventures... or maybe not. For now, I have a parser to write. Wish me luck!